一、Kafka简介
1、简介
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。
Apache的Kafka™是一个分布式流平台(a distributed streaming platform)。这到底意味着什么?
我们认为,一个流处理平台应该具有三个关键能力:
(1)它可以让你发布和订阅记录流。在这方面,它类似于一个消息队列或企业消息系统。
(2)它可以让你持久化收到的记录流,从而具有容错能力。
(3)它可以让你处理收到的记录流。
Kafka擅长哪些方面?
它被用于两大类应用:
(1)建立实时流数据管道从而能够可靠地在系统或应用程序之间的共享数据
(2)构建实时流应用程序,能够变换或者对数据
(3)进行相应的处理。
想要了解Kafka如何具有这些能力,让我们从下往上深入探索Kafka的能力。
首先,明确几个概念:
(1)Kafka是运行在一个或多个服务器的集群(Cluster)上的。
(2)Kafka集群分类存储的记录流被称为主题(Topics)。
(3)每个消息记录包含一个键,一个值和时间戳。
Kafka有四个核心API:
(1)生产者 API 允许应用程序发布记录流至一个或多个Kafka的话题(Topics)。
(2)消费者API允许应用程序订阅一个或多个主题,并处理这些主题接收到的记录流。
(3)Streams API允许应用程序充当流处理器(stream processor),从一个或多个主题获取输入流,并生产一个输出流至一个或多个的主题,能够有效地变换输入流为输出流。
(4)Connector API允许构建和运行可重用的生产者或消费者,能够把 Kafka主题连接到现有的应用程序或数据系统。例如,一个连接到关系数据库的连接器(connector)可能会获取每个表的变化。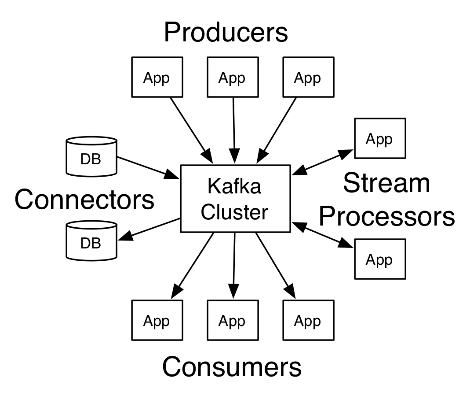
2、应用场景
主要应用场景是:
(1)构建实时的流数据管道,可靠地获取系统和应用程序之间的数据。
(2)构建实时流的应用程序,对数据流进行转换或反应。
Kafka主要设计目标如下:
(1)以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
(2)高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
(3)支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
(4)同时支持离线数据处理和实时数据处理。
3、Kafka的设计原理分析
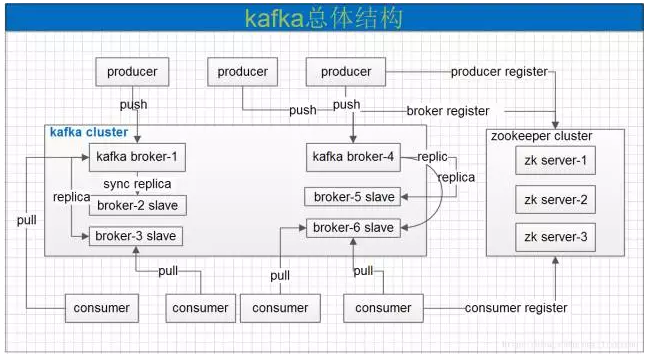
一个典型的kafka集群中包含若干producer,若干broker,若干consumer,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。producer使用push模式将消息发布到broker,consumer使用pull模式从broker订阅并消费消息。
Kafka专用术语:
Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。每个消息(也叫作record记录,也被称为消息)是由一个key,一个value和时间戳构成。
Topic:一类消息,Kafka集群能够同时负责多个topic的分发。
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
Segment:partition物理上由多个segment组成。
offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息。
Producer:负责发布消息到Kafka broker,可以理解为生产者。
Consumer:消息消费者,向Kafka broker读取消息的客户端,可以理解为生产者。
Consumer Group:每个Consumer属于一个特定的Consumer Group。
topic: 消息以topic为类别记录,Kafka将消息种子(Feed)分门别类,每一类的消息称之为一个主题(Topic)。
4、主题(Topic)和日志(Logs)
作为Kafka对数据提供的核心抽象,主题是发布的数据流的类别或名称。主题在Kafka中,总是支持多订阅者的; 也就是说,主题可以有零个,一个或多个消费者订阅写到相应主题的数据. 对应每一个主题,Kafka集群会维护像一个如下这样的分区的日志: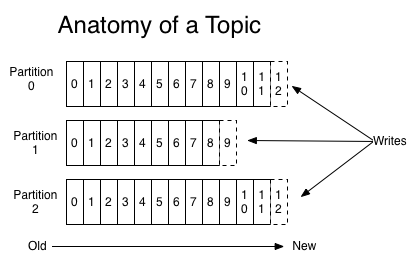
每个分区都是是一个有序的,不可变的,并且不断被附加的记录序列,—也就是一个结构化提交日志(commit log)。为了保证唯一标性识分区中的每个数据记录,分区中的记录每个都会被分配一个一个叫做偏移(offset)顺序的ID号。通过一个可配置的保留期,Kafka集群会保留所有被发布的数据,不管它们是不是已经被消费者处理。例如,如果保留期设置为两天,则在发布记录后的两天内,数据都可以被消费,之后它将被丢弃以释放空间。 卡夫卡的性能是不为因为数据量大小而受影响的,因此长时间存储数据并不成问题。事实上,在每个消费者上保留的唯一元数据是消费者在日志中的偏移位置。这个偏移由消费者控制:通常消费者会在读取记录时线性地提高其偏移值(offset++),但实际上,由于偏移位置由消费者控制,它可以以任何顺序来处理数据记录。事实上,在每个消费者上保留的唯一元数据是消费者在日志中的偏移位置。这个偏移由消费者控制:通常消费者会在读取记录时线性地提高其偏移值(offset++),但实际上,由于偏移位置由消费者控制,它可以以任何顺序来处理数据记录。
5、数据的分配(Distribution)
在Kafka集群中,不同分区日志的分布在相应的不同的服务器节点上,每个服务器节点处理自己分区对应的数据和请求。每个分区都会被复制备份到几个(可配置)服务器节点,以实现容错容灾。 分布在不同节点的同一个分区都会有一个服务器节点作为领导者(”leader”)和0个或者多个跟随者(”followers”),分区的领导者会处理所有的读和写请求,而跟随者只会被动的复制领导者。如果leader挂了, 一个follower会自动变成leader。每个服务器都会作为其一些分区的领导者,但同时也可能作为其他分分区的跟随者,Kafka以此来实现在集群内的负载平衡。
6、生产者
生产者将数据发布到他们选择的主题。 生产者负责选择要吧数据分配给主题中哪个分区。这可以通过循环方式(round-robin)简单地平衡负载,或者可以根据某些语义分区(例如基于数据中的某些关键字)来完成。
7、消费者
消费者们使用消费群组名称来标注自己,几个消费者共享一个组群名,每一个发布到主题的数据会被传递到每个消费者群组中的一个消费者实例。 消费者实例可以在不同的进程中或不同的机器上。 如果所有的消费者实例具有相同的消费者组,则记录将在所有的消费者实例上有效地负载平衡,每个数据只发到了一个消费者 如果所有的消费者实例都有不同的消费者群体,那么每个记录将被广播给所有的消费者进程,每个数据都发到了所有的消费者。
8、Kafka作为消息系统
消息系统传统上有两种模式: 队列和发布-订阅. 在队列中,消费者池可以从服务器读取,每条记录都转到其中一个; 在发布订阅中,记录将广播给所有消费者。 这两个模型中的每一个都有优点和缺点。 排队的优点是它允许您在多个消费者实例上分配数据处理,从而可以扩展您的处理。 不幸的是,队列支持多用户,一旦一个进程读取数据就没有了。 发布订阅允许您将数据广播到多个进程,但无法缩放和扩容,因为每个消息都发送给每个订阅用户。 卡夫卡消费群体概念概括了这两个概念。 与队列一样,消费者组允许您通过一系列进程(消费者组的成员)来划分处理。 与发布订阅一样,Kafka允许您将消息广播到多个消费者组。 Kafka模型的优点是,每个主题都具有这两个属性,它可以进行缩放处理,也是多用户的,没有必要选择一个而放弃另一个。 卡夫卡也比传统的消息系统有更强大的消息次序保证。 传统队列在服务器上保存顺序的记录,如果多个消费者从队列中消费,则服务器按照存储顺序输出记录。 然而,虽然服务器按顺序输出记录,但是记录被异步传递给消费者,所以它们可能会在不同的消费者处按不确定的顺序到达。 这意味着在并行消耗的情况下,记录的排序丢失。 消息传递系统通常通过使“唯一消费者”的概念只能让一个进程从队列中消费,但这当然意味着处理中没有并行性。 卡夫卡做得更好。通过分区,在一个主题之内的并行处理,Kafka能够在消费者流程池中,即提供排序保证,也负载平衡。这是通过将主题中的分区分配给消费者组中的消费者来实现的,以便每一个分区由组中的一个消费者使用。 通过这样做,我们确保消费者是该分区的唯一读者,并按顺序消耗数据。 由于有许多分区,这仍然平衡了许多消费者实例的负载。 但是请注意,消费者组中的消费者实例个数不能超过分区的个数。
9、Kafka作为存储系统
任何允许发布消息,解耦使用消息的消息队列,都在本质上充当传输中途消息的存储系统。 卡夫卡的不同之处在于它是一个很好的存储系统。 写入Kafka的数据写入磁盘并进行复制以进行容错。 Kafka允许生产者等待写入完成的确认,这样在数据完全复制之前,写入是未完成的,并且即使写入服务器失败,也保证持久写入。 Kafka的磁盘结构使用可以很好的扩容,无论您在服务器上是否有50KB或50TB的持久数据,Kafka都能保持稳定的性能。 由于对存储花费了很多精力,并允许客户端控制其读取位置,您可以将Kafka视为,专用于高性能,低延迟的日志存储复制和传播的专用分布式文件系统。任何允许发布消息,解耦使用消息的消息队列,都在本质上充当传输中途消息的存储系统。 卡夫卡的不同之处在于它是一个很好的存储系统。 写入Kafka的数据写入磁盘并进行复制以进行容错。 Kafka允许生产者等待写入完成的确认,这样在数据完全复制之前,写入是未完成的,并且即使写入服务器失败,也保证持久写入。 Kafka的磁盘结构使用可以很好的扩容,无论您在服务器上是否有50KB或50TB的持久数据,Kafka都能保持稳定的性能。 由于对存储花费了很多精力,并允许客户端控制其读取位置,您可以将Kafka视为,专用于高性能,低延迟的日志存储复制和传播的专用分布式文件系统。
10、Kafka用于流数据处理
仅读取,写入和存储数据流是不够的,Kafka的目的是实现流的实时处理。 在Kafka中,流处理器的定义是:任何从输入主题接收数据流,对此输入执行一些处理,并生成持续的数据流道输出主题的组件。 例如,零售应用程序可能会收到销售和出货的输入流,并输出根据该数据计算的重新排序和价格调整的输出流。 当然我们也可以直接用producer and consumer APIs在做简单的出列. 然而对于更复杂的转换,Kafka提供了一个完全集成的Streams API。这允许我们构建应用程序进行更复杂的运算,或者聚合,或将流连接在一起。 该设施有助于解决这种类型的应用程序面临的困难问题:处理无序数据,重新处理输入作为代码更改,执行有状态计算等。 Stream API基于Kafka提供的核心原语构建:它使用生产者和消费者API进行输入,使用Kafka进行有状态存储,并在流处理器实例之间使用相同的组机制来实现容错。仅读取,写入和存储数据流是不够的,Kafka的目的是实现流的实时处理。 在Kafka中,流处理器的定义是:任何从输入主题接收数据流,对此输入执行一些处理,并生成持续的数据流道输出主题的组件。 例如,零售应用程序可能会收到销售和出货的输入流,并输出根据该数据计算的重新排序和价格调整的输出流。 当然我们也可以直接用producer and consumer APIs在做简单的出列. 然而对于更复杂的转换,Kafka提供了一个完全集成的Streams API。这允许我们构建应用程序进行更复杂的运算,或者聚合,或将流连接在一起。 该设施有助于解决这种类型的应用程序面临的困难问题:处理无序数据,重新处理输入作为代码更改,执行有状态计算等。 Stream API基于Kafka提供的核心原语构建:它使用生产者和消费者API进行输入,使用Kafka进行有状态存储,并在流处理器实例之间使用相同的组机制来实现容错。
综上所述:
消息系统,数据存储和流处理的这种组合似乎是不寻常的,但是这些特性对于Kafka作为流媒体平台的角色至关重要。 像HDFS这样的分布式文件系统允许存储用于批处理的静态文件。 本质上,这样的系统允许存储和处理来自过去的历史数据。 传统的企业邮消息系统允许处理将在您订阅之后到达的未来消息。 以这种方式构建的应用程序在未来数据到达时即使处理。 Kafka结合了这两种功能,这种组合对于Kafka作为流应用程序和流数据管道平台来说至关重要。 通过组合存储和低延迟订阅,流式应用程序可以以相同的方式处理过去和未来的数据。 这是一个单一的应用程序可以处理历史记录数据,而不是在到达最后一个记录时结束,它可以随着将来的数据到达而继续处理。 这是一个广泛的流处理概念,其中包含批处理以及消息驱动应用程序。 同样,对于流数据流水线,订阅到实时事件的组合使得可以使用Kafka进行非常低延迟的管道传输; 可靠地存储数据的能力使得可以将其用于必须保证数据传送的关键数据,或者与仅负载数据的离线系统集成,或者可能会长时间停机以进行维护。流处理功能在数据到达时进行数据转换处理。
二、Kafka安装
Kafka需要Zookeeper的监控,所以先要安装Zookeeper。新版本Kafka拥有自带的zookeeper,也可以不用安装zookeeper,根据选择的kafka版本确定。
Zookeeper需要java环境支持,所以先要安装jdk。
1、JDK安装
检查系统是否已经安装jdk1
java -version
如果没有显示java版本信息,则表示没有安装java1
2
3
4
5
6
7
8
9
10#安装java
tar -zxvf jdk-8u161-linux-x64.tar.gz
mv jdk1.8.0_161 /data/jdk1.8
#修改系统变量
vi /etc/profile
#在文本末尾添加以下内容:
PATH=/data/jdk1.8/bin:$PATH
export PATH
#使添加内容生效
source /etc/profile
再查看java版本 出现如下信息表示安装成功1
2
3
4# java -version
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
2、Zookeeper安装
官网下载地址:http://apache.fayea.com/zookeeper/stable/
Zookeeper属于可选安装1
2
3
4
5
6
7
8
9
10
11#下载
wget http://apache.fayea.com/zookeeper/stable/zookeeper-3.4.10.tar.gz
tar -zxvf zookeeper-3.4.10.tar.gz
mv zookeeper-3.4.10 /data/zookeeper
cd /data/zookeeper/
#创建数据目录
mkdir /data/zookeeper/data
cd conf/
#创建配置文件
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
zoo.cfg修改后为1
2
3
4
5tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
clientPort=2181
配置环境变量:vim /etc/profile,加入以下内容1
2export ZOOKEEPER_HOME=/data/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
source /etc/profile使新增加环境变量生效
zookeeper相关命令1
2
3
4
5
6#开启
/data/zookeeper/bin/zkServer.sh start
#停止
/data/zookeeper/bin/zkServer.sh status
#查看状态
/data/zookeeper/bin/zkServer.sh status
3、Kafka安装
官网下载地址:http://kafka.apache.org/downloads
本次下载最新版本1
2
3wget http://mirror.bit.edu.cn/apache/kafka/1.1.0/kafka_2.12-1.1.0.tgz
tar -zxvf kafka_2.12-1.1.0.tgz
mv kafka_2.12-1.1.0 /data/kafka
修改配置文件1
2cd /data/kafka/
vim config/server.properties
Server.properties修改后为1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19broker.id=0
port=9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/logs/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
修改关于zookeeper的配置文件zookeeper.properties1
vim config/zookeeper.properties
zookeeper.properties修改后为1
2
3dataDir=/data/kafka/zkdata
clientPort=2181
maxClientCnxns=0
在kafka目录启动zookeeper1
2cd /data/kafka
bin/zookeeper-server-start.sh config/zookeeper.properties &
启动kafka1
bin/kafka-server-start.sh config/server.properties &
以后台方式启动1
2
3
4#zookeeper
nohup zookeeper-server-start.sh /data/kafka/config/zookeeper.properties 1>/dev/null 2>&1 &
#kafka
nohup kafka-server-start.sh /data/kafka/config/server.properties 1>/dev/null 2>&1 &
kafka启动时候需要zookeeper,可以使用单独的zookeeper,也可以启动kafka中已集成的zookeeper。

