一、前言
1、为什么用ELK
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
* 收集-能够采集多种来源的日志数据
* 传输-能够稳定的把日志数据传输到中央系统
* 存储-如何存储日志数据
* 分析-可以支持 UI 分析
* 警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
2、ELK简介
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Filebeat隶属于Beats。目前Beats包含四种工具:
(1)Packetbeat(搜集网络流量数据)
(2)Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
(3)Filebeat(搜集文件数据)
(4)Winlogbeat(搜集 Windows 事件日志数据)
3、设计架构
1)简单架构
一般最简单的架构只用elasticsearch、logstash、kibana组成即可,如下图:
logstash收集处理数据,并输出到elasticsearch
elasticsearch存储日志数据
kibana用于数据的检索、查询、web展示
2)高可用架构
随着业务、性能、稳定性等需求的增加,架构中引进filebeat和缓存机制,如下图
filebeat:用于收集数据,替代logstash,在每台agent端需要部署,相比于logstash,filebeat占用更少的系统资源
缓存集群:可以使用kafka或者redis,使日志的汇总处理更快速
logstash集群:提高日志管道的传输速度和系统性能
elasticsearch集群:存储日志数据
kibana集群:提高web的访问负载能力,前端使用nginx代替
这种架构中各节点使用集群替代,具有更大的负载能力和数据处理能力。
二、 安装
1、环境准备
修改/etc/sysctl.conf,并使之生效1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# cat /etc/sysctl.conf |grep vm.max
vm.max_map_count=262144
[root@izuf63k1rfnrzs6zc1g95qz elasticsearch-head]# sysctl -p /etc/sysctl.conf
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
vm.swappiness = 0
net.ipv4.neigh.default.gc_stale_time = 120
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.default.arp_announce = 2
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_announce = 2
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 1024
net.ipv4.tcp_synack_retries = 2
kernel.sysrq = 1
vm.max_map_count = 262144
修改/etc/security/limits.conf,添加以下两行1
2
3# cat /etc/security/limits.conf |grep elasticsearch
elasticsearch soft nofile 65536
elasticsearch hard nofile 65536
关于网络设置和端口开放部分不再描述,使用端口可以根据自己需求修改。
2、elasticsearch安装
ELK官网地址:https://www.elastic.co/
Elasticsearch需要java环境支持,请自行安装。
需要的安装文件自行下载,不再给予下载地址。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# tar -zxvf elasticsearch-6.3.2.tar.gz
# mv elasticsearch-6.3.2 /data/elasticsearch
创建用户和用户组
groupadd elasticsearch #新建elsearch组
useradd elasticsearch -g elasticsearch -p elasticsearch #新建一个elsearch用户
chown -R elasticsearch.elasticsearch /data/elasticsearch #对文件夹授权
配置elasticsearch
# cd /data/elasticsearch
# cat config/elasticsearch.yml |grep -v '^#'|grep -v '^$'
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: false
network.host: 0.0.0.0
http.port: 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
切换用户,启动elasticsearch
# su elasticsearch
$ /data/elasticsearch/bin/elasticsearch -d
-d是以后台进程方式启动
浏览器访问,如下图
表示安装成功,也可以使用curl方式访问。
3、logstash安装
Logstash安装可以切换到root用户进行安装1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# tar -zxvf logstash-6.3.2.tar.gz
# mv logstash-6.3.2 /data/logstash
配置logstash
# cd /data/logstash/
# mkdir conf.d
# cat config/logstash.yml |grep -v '^$'|grep -v '^#'
path.config: /data/logstash/conf.d
path.logs: /data/logstash/logs
# cat conf.d/logstash_test.conf
input{
file{
path =>"/data/work/logs/MsgService.log"
start_position=>"beginning"
}
}
output{
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "MsgService-%{+YYYY.MM.dd}"
}
stdout{
codec=>rubydebug
}
}
启动并验证1
# /data/logstash/bin/logstash -f /data/logstash/conf.d/logstash_test.conf --path.data=/data/logstash/data/002
出现以下格式信息表示启动成功1
2
3
4
5
6
7{
"message" => "2018-07-19 10:18:23.431 INFO 21554 --- [tbeatExecutor-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_MSGSERVICE/172.19.254.54:23000/msgService - registration status: 204",
"path" => "/data/work/logs/MsgService.log",
"@timestamp" => 2018-07-26T08:43:43.081Z,
"host" => "izuf63k1rfnrzs6zc1g95qz",
"@version" => "1"
}
logstash中input表示读取日志文件,filter表示过滤,output表示输出
具体的语法,根据不同的日志文件配置。
input、filter、output其实都是logstash的插件,根据需求我们可以安装检查和卸载插件。
通过1
# ./bin/logstash-plugin list
查看插件管理的命令帮助。
常用的命令有1
2
3
4bin/logstash-plugin list #查看已安装插件列表
bin/logstash-plugin install plugin_name #安装插件
bin/logstash-plugin update plugin_name #卸载插件
bin/logstash-plugin uninstall plugin_name #卸载插件
通过list命令查看插件列表时候,无非下列四种类型的插件:
* logstash-codec-* #编码解码插件
* logstash-filter-* #数据处理插件
* logstash-input-* #输入插件
* logstash-output-* #输出插件
此处需要完善一个概念:Logstash 不只是一个input | filter | output 的数据流,而是一个 input | decode | filter | encode | output 的数据流!上面插件中的codec 就是用来 decode、encode 事件的。
启动语句中–path.data表示指定目录,为了实现多实例启动,在配置文件中可以不配置path.data参数,在启动时候加上。
以后台方式启动1
# nohup /data/logstash/bin/logstash -f /data/logstash/conf.d/logstash_test.conf --path.data=/data/logstash/data/002 &
4、安装elasticsearch-head
elasticsearch-head从5.x版本以后不再依附于elasticsearch安装,作为独立进程安装。
elasticsearch-head项目地址:https://github.com/mobz/elasticsearch-head#connecting-to-elasticsearch
elasticsearch-head需要node环境,首先安装node,这里不贴出详细步骤。
验证node版本1
2# node -v
v8.11.3
下载安装1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# wget https://github.com/mobz/elasticsearch-head/archive/master.zip
为了后续安装phantomjs,使用bzip2解压,需要安装bzip2
# yum install bzip2 -y
解压到/data目录
# cd /data/elasticsearch-head
# npm -v
5.6.0
# npm install --registry=https://registry.npm.taobao.org --unsafe-perm
安装过程会有点慢
--registry=https://registry.npm.taobao.org表示使用国内镜像资源
--unsafe-perm表示取消秘钥验证
验证安装
# ll ./node_modules/grunt
total 32
drwxr-xr-x 2 root root 4096 Jul 26 14:03 bin
-rw-r--r-- 1 root root 7111 Apr 6 2016 CHANGELOG
drwxr-xr-x 4 root root 4096 Jul 26 14:03 lib
-rw-r--r-- 1 root root 1592 Mar 23 2016 LICENSE
drwxr-xr-x 4 root root 4096 Jul 26 14:03 node_modules
-rw-r--r-- 1 root root 2442 Jul 26 14:03 package.json
-rw-r--r-- 1 root root 878 Feb 12 2016 README.md
修改配置Gruntfile.js,增加hostname,如下图所示
启动1
npm run start
浏览器访问
比如我们在服务器上配置,但是在本地通过外网访问elasticsearch-head,那么elasticsearch的地址不应该是elasticsearch所在服务器的内网地址,而应该是外网地址,注意对应使用的端口应该打开。
elasticsearch-head是一个查看集群信息的工具,我们现在只配置一台elasticsearch,如果是多台,也可以用于查看集群内其他elasticsearch信息。
查看页面表示安装成功。
以后台方式运行1
# nohup npm run start &
5、kibana安装
1 | 解压配置 |
浏览器访问后,配置index pattern,根据日志index标识不同,自己灵活掌握。
6、kibana汉化
对于习惯使用英文界面的也可以不用汉化。
1)官网汉化方式
ELK6.x版本提供国际化的标准,可以自己翻译汉化
1、复制src/core_plugins/kibana/translations/en.json的内容,创建一个新的json文件,比如ch.json。
2、翻译并修改ch.json中对应的文字。
3、 在src/core_plugins/kibana/index.js文件中,找到translations,然后添加对应的内容。
4、 最后在配置文件config/kibana.yml(开发模式下,创建并使用配置文件kibana.dev.yml)中,加入默认的语言设置:i18n.defaultLocale: “ch”
5、 等kibana服务器重启之后,刷新页面就可以看见效果了。
2)github个人项目翻译方式
项目地址:https://github.com/anbai-inc/Kibana_Hanization
具体的使用方法也有介绍,但是非官方方法,具体的效果不太理想。
个人认为6.x版本使用此方法汉化后会影响系统启动。
三、高级配置
1、filebeat安装
1 | 下载地址https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.3.2-linux-x86_64.tar.gz |
6.x版本中filebeat,只支持一个output输出,如果把日志输出到elasticsearch,则需要把输出到logstash段配置注释。一般情况下输出到logstash,进行过滤,再由logstash输出到elasticsearch。
启动1
nohup ./filebeat -c filebeat.yml &
同一台服务器上可以启动多个filebeat,但是需要指定不同的配置文件。
2、logstash相关配置
主要配置如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# cat /data/logstash/conf.d/logstash_test.conf
input{
beats {
port => 5044
}
}
output{
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "MsgService-%{+YYYY.MM.dd}"
}
# stdout{
# codec=>rubydebug
# }
}
Index定义日志头
Logstash可以根据conf和path.data的不同启动多个进程
3、filter配置
filter主要对日志进行过滤和筛选,以剔除不必要的日志,使用的方法为grok。
grok中配置macth来匹配日志,使用正则表达式。相关正则表达式字段可以查看github:https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/grok-patterns
匹配的验证测试可以使用以下地址:
https://grokconstructor.appspot.com/do/match
http://grokdebug.herokuapp.com/
个人体验,推荐使用第一个地址,需要使用科学上网。
实例:
1、匹配nginx access的日志
nginx中access日志的模式配置为1
2
3log_format main '$remote_addr $remote_user $time_local $request '
'$http_referer $status $body_bytes_sent $request_body '
'"$http_user_agent" "$http_x_forwarded_for"';
验证匹配字段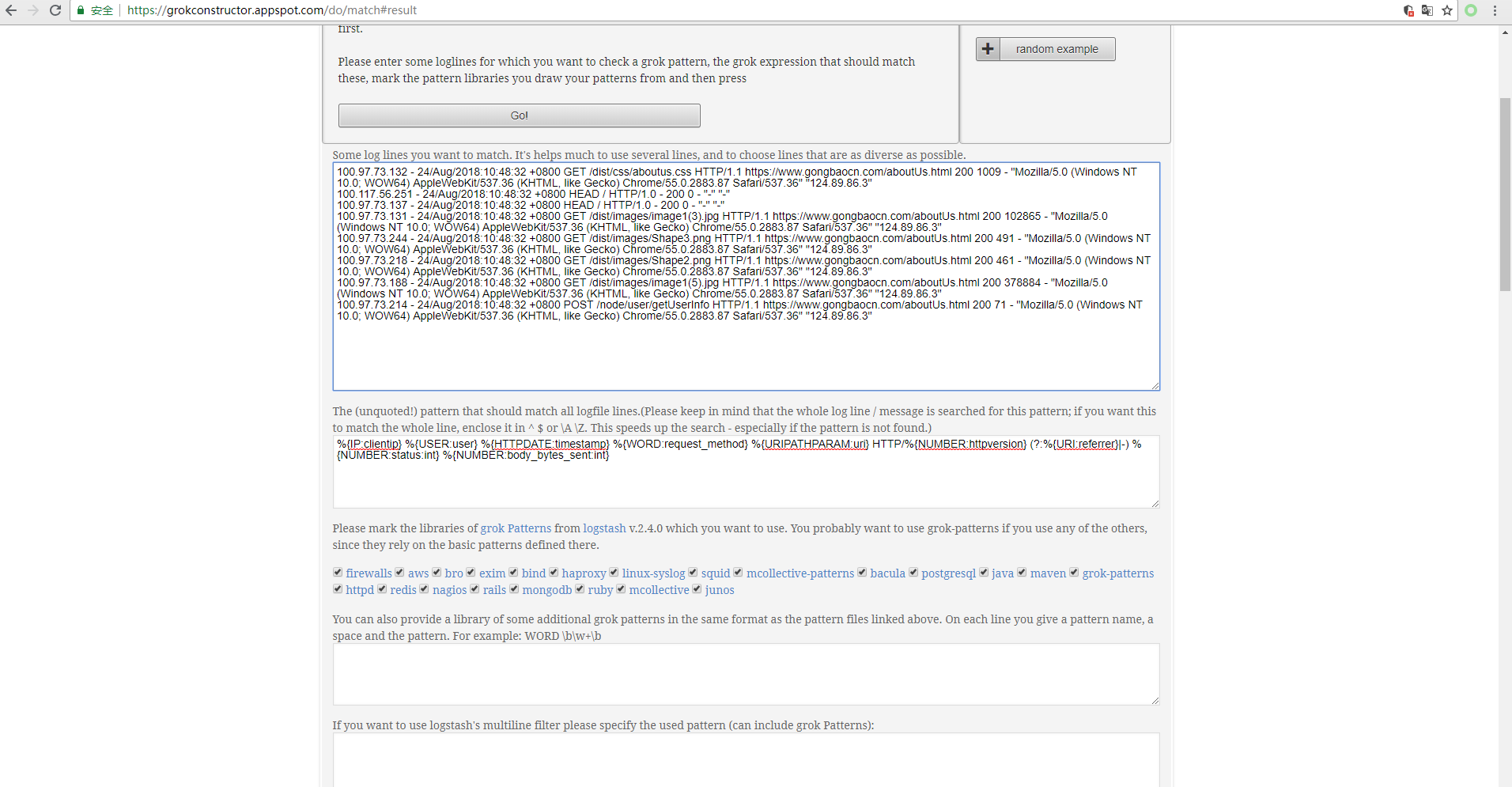
其中第一个框内为nginx access的日志
第二个框内为匹配准则,准则的大写字段是从github地址上查找得到,小写字段为自定义
执行,得到如下所示
可以看到匹配完成,match即为匹配准则,日志中不重要的部分可以不进行匹配。
将match写入logstash配置文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32# cat conf.d/nginx_access_log.conf
input{
beats {
port => 5055
}
}
filter {
grok {
match => ["message","%{IP:clientip} %{USER:user} %{HTTPDATE:timestamp} %{WORD:request_method} %{URIPATHPARAM:uri} HTTP/%{NUMBER:httpversion} (?:%{URI:referrer}|-) %{NUMBER:status:int} %{NUMBER:body_bytes_sent:int} "]
}
# if [loglevel] == "DEBUG" {
# drop {}
# }
if [uri] == "/" {
drop {}
}
}
output{
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "nginx_access_log-%{+YYYY.MM.dd}"
}
# stdout{
# codec=>rubydebug
# }
}
drop是跟字段匹配进行过滤,过滤掉的日志将不会再进行output。
此处drop掉的是slb的检测访问的日志,即非业务的日志。
需要注意的是:对message进行匹配,后面的准测内不允许使用多个””,所以在nginx的配置文件内需要修改日志格式的相关字段,不要加双引号。
2、匹配nodejs的日志
验证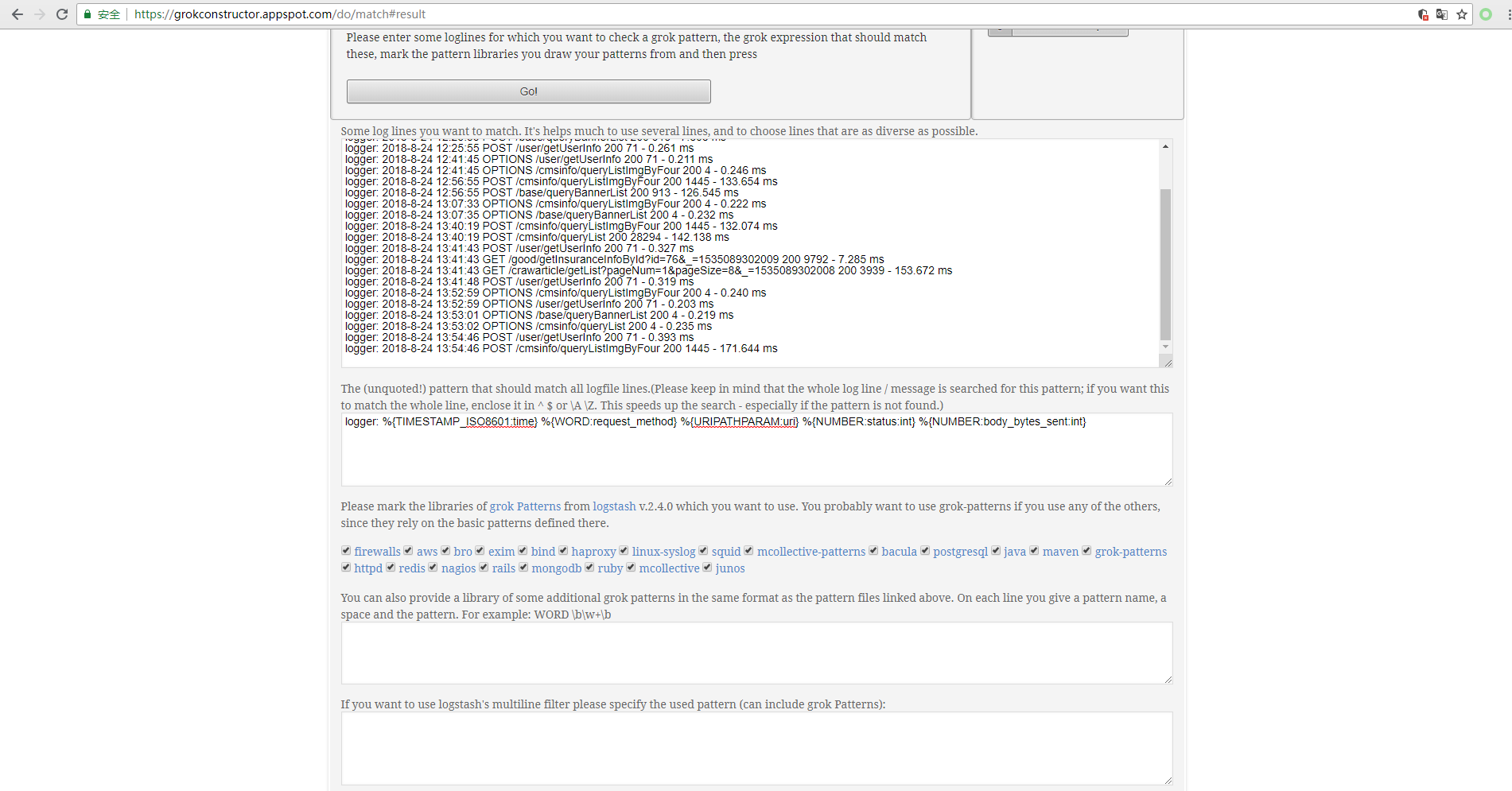
执行,查看结果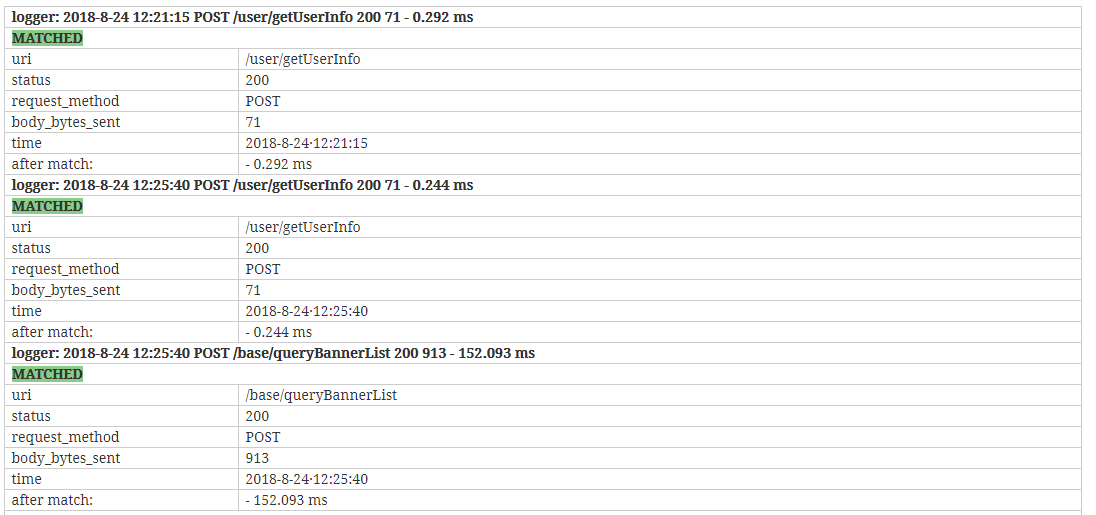
关于每条日志的记录的行为的相应时间是没有进行匹配的,所以出现在after match处。
写入logstash配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32# cat conf.d/nodejs_log.conf
input{
beats {
port => 5077
}
}
filter {
grok {
match => ["message","logger: %{TIMESTAMP_ISO8601:time} %{WORD:request_method} %{URIPATHPARAM:uri} %{NUMBER:status:int} %{NUMBER:body_bytes_sent:int} "]
}
# if [loglevel] == "DEBUG" {
# drop {}
# }
# if [uri] == "/" {
# drop {}
# }
}
output{
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "nodejs_log-%{+YYYY.MM.dd}"
}
# stdout{
# codec=>rubydebug
# }
}
以上配置是没有对日志进行drop操作的,日志是否需要进行drop根据实际情况操作。
3、匹配java的日志
java是世界上最不友好的语言,反正我就是这么认为!
java的日志格式不像web应用暴露的日志一样格式规范,所以很难匹配。
如下所示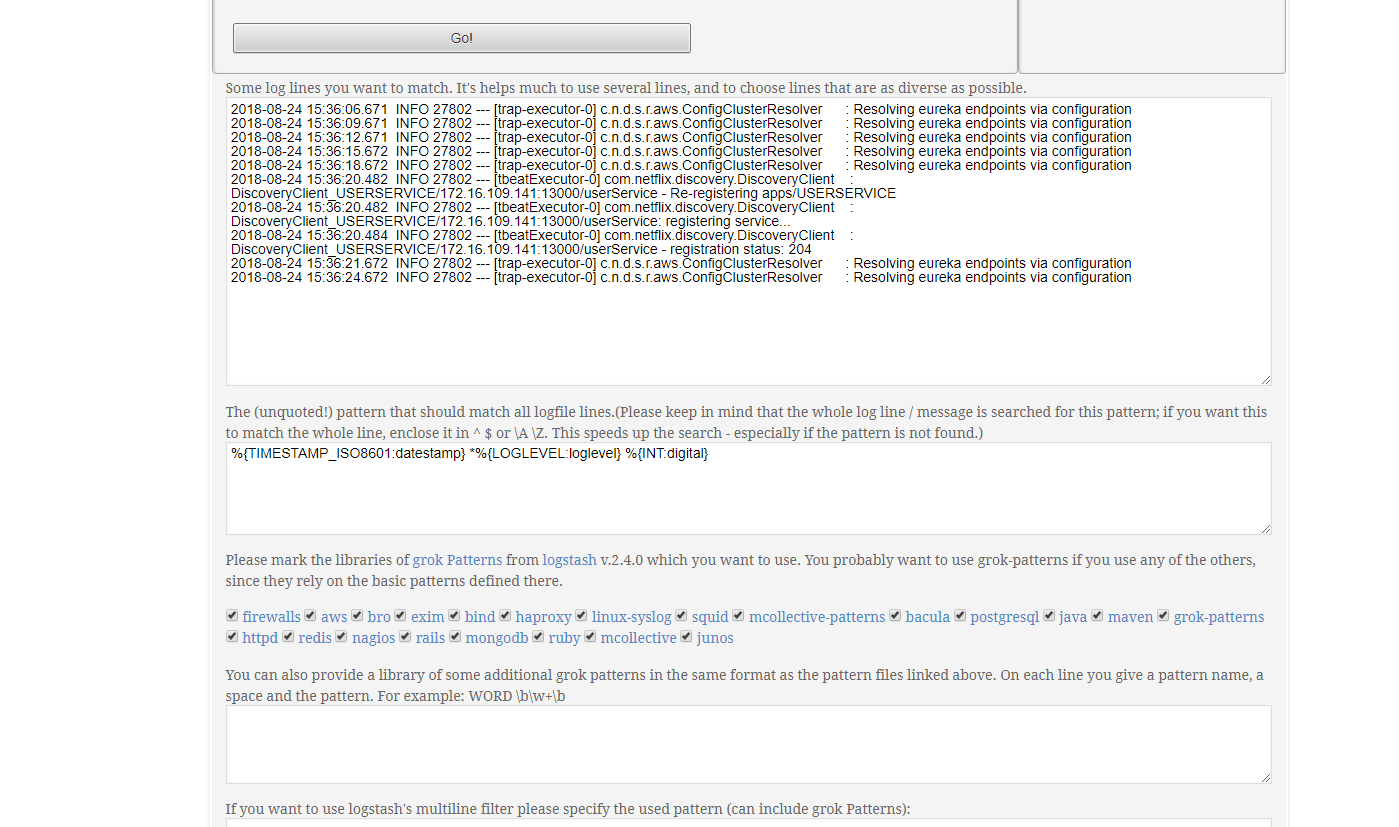

after match部分毫无规律,不知道这是什么玩意儿,就不匹配了,够用就行。
添加logstash配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33# cat conf.d/springcloud_log.conf
input{
beats {
port => 5044
}
}
filter {
grok {
match => ["message","%{TIMESTAMP_ISO8601:datestamp} *%{LOGLEVEL:loglevel} %{INT:digital} *"]
}
# if [loglevel] == "DEBUG" {
# drop {}
# }
if [loglevel] == "INFO" {
drop {}
}
}
output{
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "springcloud_log-%{+YYYY.MM.dd}"
}
# stdout{
# codec=>rubydebug
# }
}
此处drop的为类型是INFO的日志。
4、其他配置
关于elasticsearch和kibana的配置不用调整。

